Dependency of a function on Row Context in DAX
- Antriksh Sharma

- Nov 18, 2021
- 4 min read
Updated: Dec 22, 2021
Have you ever writen a piece of DAX Code that looks like this:

and ended up confused how is it able to calculate how many years, days, months etc are less than or equal to the MAX ()? Worry not this is the goal of this blog to clear the doubt on how MAX is actually working here.
To begin with the first thing that you need to recall is there are always 2 types of evaluation context at max when your DAX code is evaluated. Filter Context and Row Context.
Filter Context
Created implicitly by the visuals because of the grouping of columns
Created by users by selecting values on a visual or a slicer or a filter pane
Can be created programmatically by using CALCULATE/CALCULATETABLE only
Filters the whole data model through the chain of relationships, moves naturally from 1 to many side using uni-directional crossfilter and can be moved upstream from many to 1 side using bi-directional crossfilter either in the relationship or by using CROSSFILTER function inside CALCULATE/CALCULATETABLE
Row Context
Created automatically by Calculated Columns
Doesn't exists automatically for measures
Can be created programmatically by using any iterator such as SUMX, MINX, AVERAGEX, MAXX, ADDCOLUMNS, SUMMARIZE, GENERATE etc
It only iterates a table
To access a corresponding row(s) from other table(s) you need to use RELATED or RELATEDTABLE
Apart from this general recap, you should also remember that Filter Context filters and doesn't iterate and similarly Row Context iterates and doesn't filters.
Now coming back to the code, what is happening here, what is evaluated and where?
This is the order of operation:
ALL gets all the unique values of the Calendar Year Column including any blank row if available
FILTER creates a row context on the table returned by ALL
MAX evaluates the value of the column in the Filter Context that exists outside of FILTER
For each row that is iterated by FILTER a boolean operation is done to check whether the currently iterated value is less than or equal to the value that is returned by MAX
Now you might think that MAX should use the value from the row context/currently iterated row, the thing is that doesn't make sense, if every time a new row is iterated and MAX takes the value from the row context, then it will always return the same values as of the one that is currently iterated and we will never get the correct number.
If you are in doubt you can split the code into variables and then you can see that MAX definitely doesn't depends on the row context created by FILTER.

To make what I am trying to understand even easier let's fire up DAX studio to understand what is actually happening behind the scenes and whether if the MAX function is actually dependent on the row currently iterated by FILTER
We need to use the Query Plan option and I have mimiced the same query that Power BI generates behind a visual, I haven't included the subtotal part just so that query plan is easier to read.
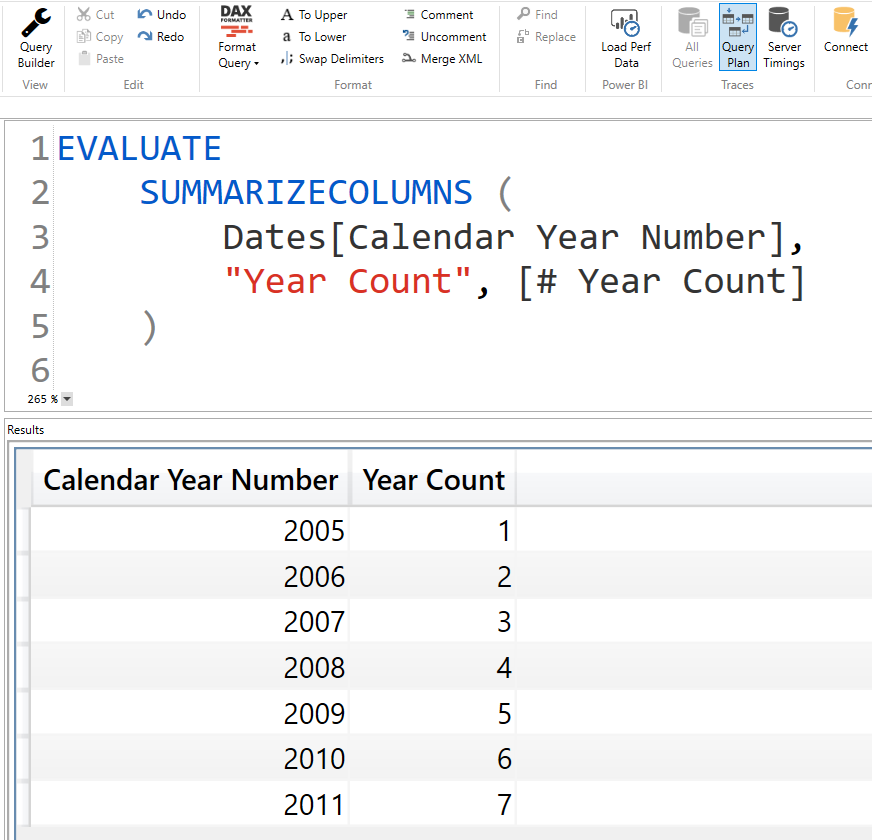
In particular we are only interested in the Logical Query plan as it shows the Column numbers that helps us in differentiating between same column extracted mulitple times by the engine for different use cases.
The below image is the Logical Query Plan for the DAX expression that we have seen so far.

Pay attention to the first word of each line, the first word in itself is self sufficient in providing enough information about what is happening at that stage.
For example at line 3 we have CountRows operator which corresponds to COUNTROWS function, for counting the rows then we have a Filter operator which corresponds to FILTER, since FILTER need 1 column then we have a Scan_Vertipaq event that gets 1 column from the Storage Engine - Vertipaq, the column here is Date[Calendar Year Number] with identifier listed before it as RequiredCols(1), the 1 here is really important as it helps us in keeping track of where the particular column is getting re-used.
Then at the Line 8 we have a Max_Vertipq operator that corresponds to MAX function in our code and on the same line we have DependOnCols(0)(Dates[Calendar Year Number]) written which tells us that for the MAX to be computed the Max_Vertipaq event depends on a particular column that is marked as 0, so what is 0 here? Go back to line 2 and you will see Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Dates'[Calendar Year Number]) The Calendar Year Column Referenced here is the column that is used by SUMMARIZECOLUMNS for creating the axis of our report and only on this column the MAX function depends and not on the column marked as 1 Dates[Calendar Year Number]. And as I have already mentioned earlier the initial filter context in most visual is created by grouping of the columns used in the visual, so similarly the filter context for MAX here is created by the column used inside SUMMARIZECOLUMNS.
Also on Line 9 we have a Scan_Vertipaq Operator which says that for computing MAX, the MAX function depends on 0 and the required columns are (0, 5) Dates[Calendar Year Number] and Dates[Calendar Year Number], this simply means that for computing MAX another scan of the same column is required.
Now that was a query plan for a code that didn't use Variables, let's take a look at the version which use variables so that it is even easier to keep a track of the dependency.
This time a query plan is a bit longer, but trust me using variables is a much better option.

Now you can see that from line 4 - 6 we have events/operators for computing MAX Year and it depends on 0 Dates[Calendar Year Number] which is extracted in line 2 using the Scan_Vertipaq operator.
Then from line 8 -12 we have the FILTER operation, from line 10 - 12 we see the LessThanOrEqualTo operation and on Line 12 we see ScalarVarProxy which is just reusing the variable that is declared earlier. and you can see that it never depends on the column 1 as per the Scan_Vertipaq event of line 7
All of the above explanation is also evident from the xmSQL code in the Server Timings tab:


So now you can see that using an aggregation function in row context doesn't mean that it will depend on the currently iterated row, this scenario is completely different when you use a measure reference or write CALCULATE ( MAX () ) but that is a story for some other day.
Here is a link to the post that made me create this blog.

Video version of the blog -


Comments